Information Theory #5 - City
I am writing a series of posts about Information Theory problems. You may find the previous one here.
The problem we will analyze is City from the Japanese Olympiad in Informatics Spring Camp (JOI SC 2017). You may find the problem statement and a place to submit here .
A synthesis of the problem statement is : you are given a rooted tree of N vertices (N <= 250000) that has a depth that is at most 18. You must write an integer on each node so that given only the integers written on X and Y, without knowing the structure of the tree, you can answer the question : is X on the path from Y to the root, Y on the path from X to the root or neither of them?
The scoring of the problem is based on the maximum integer you write on each node. There is also a subtask for N <= 10.
Subtask 1 : N <= 10 (8 points)
In this subtask, the graph is small and the maximum integer does not matter as long it is smaller than 2^60 - 1.
Because of this, we may choose a suboptimal strategy to solve the problem. The simplest one is to encode the vertex and the whole adjacency matrix on the integer we send.
We use the binary encoding to send the current node (this uses 4 bits) and use another 45 bits to send the matrix. Then, we run a DFS to see which case happens
L <= 2^36 - 1 : 22 points
With very big N, it is impossible to send the adjacency matrix. So we will focus on another technique to solve the problem.
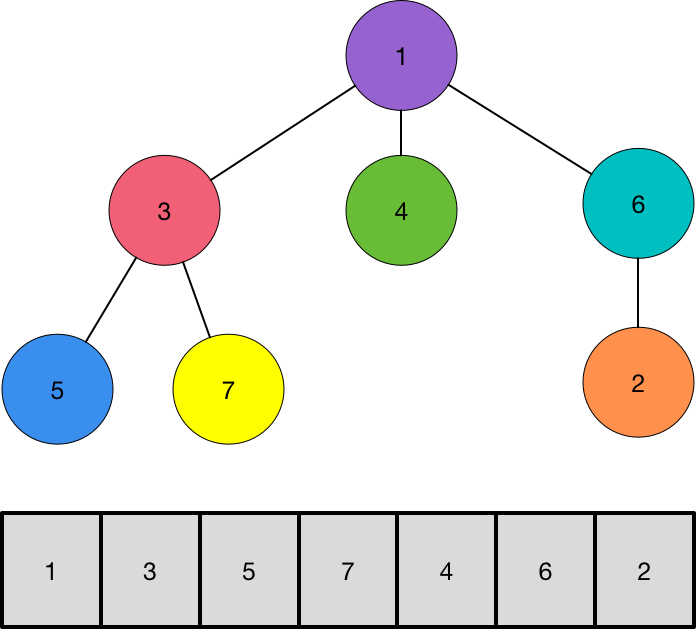
This technique is commonly called “Euler Tour on a Tree” , even tough it is not exactly an Euler Tour. You can interpret it as noticing a special property of the initial and final time when you do a DFS on the tree.
The image above represents the “Euler Tour”. Every time you enter a vertex v, you increase the DFS counter and says this is number is the start time of v . At the end of the DFS on v, we also save the DFS counter and says it is the end time of v. The vector in the image represents this DFS ordering.
The cool thing about this is that it allows us to check if a vertex u is on the subtree of a vertex v easily. Because the vertices of the subtree form a contiguous subarray in the DFS order array, we can simply check if the start of u is contained in the interval [s,e] where s is the start time of v and e the end time of v.
If you think a little bit about it, checking if a vertex v is on a subtree of another is exactly the same as checking if that another vertex is on the path from v to the root. So we found a solution to the problem we want to solve!
For each vertex, we send an integer that represents the start and end time of the DFS. To do that, we send 18 bits for the start and another 18 bits for the end. In the decoding part, we simply recover the starts and ends and run the interval check described above.
The maximum number if 2^36 - 1 , thus we score 22 points.
An unused property
So far we did not the property that the depth of the tree is at most 18. The solution described above works for any tree, and therefore does not exploit the special property of the depth.
Because the maximum depth is 18, every node has at most 18 ancestors and is therefore contained in at most 18 intervals. Thus, the sum of the lengths of all intervals is at most 18*N. So on average each interval is at most 18. That is not much.
It seems to be a waste to send 18 bits of the end when we could send the size, which is on average 5 bits. So we will do exactly that : instead of sending the end, we send the size of the interval.
This optimization alone does not affect our punctuation, because there are causes in which we will still send integers up to 2**36 - 1. However, this idea is a crucial step to solve the problem.
An efficient way of sending the size : 100 points solution
We need to optimize the way we send the size. In a perfect environment, we could create a smaller dictionary that represented the sizes and send the position in that dictionary.
However, it is difficult to adjust a dictionary to the sizes of the interval. We will try a different approach : adjust the interval size to the dictionary. But how do we do that ?
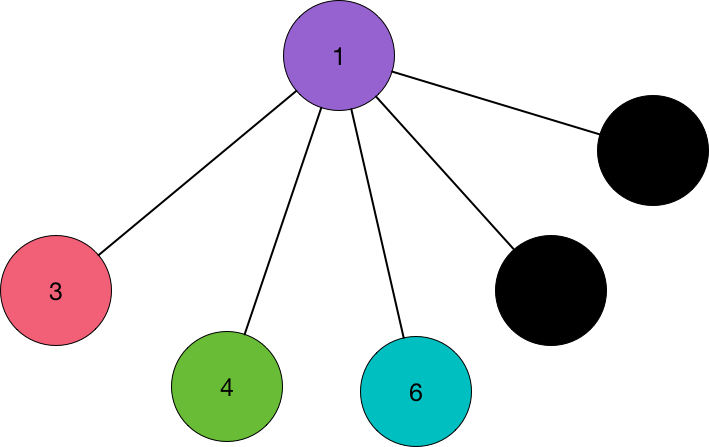
Suppose that the interval size is a. How do we fit that size to the dictionary , if it is not in it? Let b be the smallest integer of the dictionary greater than our equal to a. We can always add some extra leaves as dummy vertices in order to reach the size b. The image above exemplifies that, by adding two leaves to reach the size 5 from the original size 3.
In practice, we are adding empty spaces to our DFS array. The challenge now is to build that dictionary of sizes.
Building the dictionary : 100 points solution
The challenge of finding a dictionary of sizes is that it should not add many extra vertices, because in that case the start of the vertices would be big and thus the dictionary would need to be small.
If the total number of vertices (original and dummy) of the final solution is close to 2^K, then we must construct a dictionary of size 2^(28 - K) .
Additionally , this dictionary should vary gradually. A function that varies gradually is a power function, so we can describe our dictionary as a set of {r^0, r^1, r^2…} for some number r. The optimal r is the solution for r^(2^(28 - K)) = 2^K
If you experiment with K, you may find that K = 20 is a good choice. Therefore, the maximum number of vertices if 2^20 and the dictionary size is 2^8 = 256.
The value of r is 2^(20/256) ≈ 1.055645 (we must truncate because we cannot represent an irrational number in an exact decimal form).
Because r is not an integer, our dictionary is not exactly described by a power function, but by an approximation. Let A be our dictionary and a0 = 0 the first element. We say that ai = max{ a(i-1) + 1, ai*r } , where ai*r is rounded down.
In the final code, I opted to send the difference between the start and the end instead of the size. The result is identical, tough.